Agenda:
- Microservices Architecture
- Command and Query
- Event
- Event-Driven Architecture (EDA)
- Producer
- Channel
- Consumer
- Advantages of Event-Driven Architecture
- Orchestration and Choreography
- Event Sourcing Pattern
- CQRS Pattern
- When to use Event Sourcing and CQRS
- Stateless EDA
- Stateful EDA
- Event Streaming
- Correlation Id
- Mixing EDA with Request/Response
- Events as Source of Truth
- The Saga Pattern
1. Microservices Architecture
- Based on loosely coupled services.
- Each service is in its own process.
- Lightweight communication protocols.
- Polyglot – no platform dependency between services.
Replaces 2 legacy architectures as Monolith and SOA (Service Oriented Architecture).
The most important part in the EDA is the microservices communication. Which is dictated performance, and scalability. So the Event Driven Architecture handles the communication part.
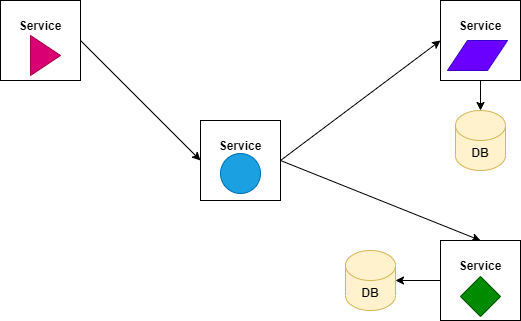
2. Command and Query
The basic methods of how services communicate with each other are the Command and Query. This is the classic communication between services. The services are:
- Send command. Service asks another service to do something. There might be a response to the command, usually a success or failure indicator.

- Query for data. Service asks another service for data. There is always a response to the query, containing the data.

Main characteristics:

The major problems with the Command and Query are:
- Performance – synchronous, the calling service waits for the command/query to complete.
- Coupling – if the called service changes – the calling service has to change too => more work, more maintenance.
- Scalability – the calling service calls a single instance of a service, if the instance is busy – there’s a performance hit. Adding other instances is possible, but difficult (add a load balancer, etc.)
3. Event
Event indicates that something happened in the system.

Main characteristics:

4. Contents of Event
There are 2 types of event data:
- Complete:
- Contains all the relevant data.
- Usually entity data.
- No additional data is required for the event processing.
- Example:
- event_type: CustomerCreated
- customer_id: 21
- first_name: Ivan
- last_name: Smith
- join_date: 16/12/2022
- Pointer:
- Contains a pointer to the complete data of the entity
- Complete data usually stored in a database
- Event handler needs to access the database to retrieve complete data.
- Example:
- event_type: CustomerCreated
- customer_id: 21
Flow of Complete Event Handling:

Flow of Pointer Event Handling:
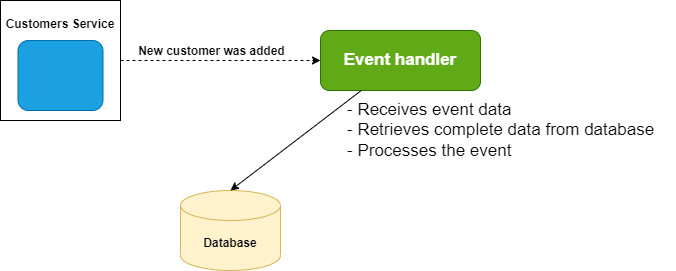
When to use the Complete Flow:
- The better approach.
- Makes the event completely autonomous.
- Can get out of the system boundaries.
When to use the Pointer Flow:
- Data is large.
- Need to ensure data is up to date – assuming database is a single source of truth.
5. Producer
Producer (Publisher) is a component/service that sends the event. Usually sends event reporting when something done.
For example:
- Customer Service => New Customer Added event.
- Inventory Service => Item Sold Out event.
The Producer sends the event to the Channel, usually it using a dedicated SDK developed by the channel vendor. Utilizes some kind of network call, usually with specialized ports and proprietary protocol. I.e.: RabbitMQ listens on port 5672 and uses the AMQP protocol. The Producer can be developed using and development language.
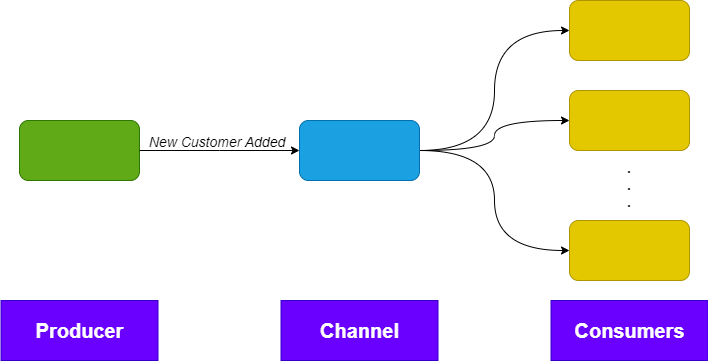
6. Channel
The Channel is the most important component in the Event-Driven Architecture. It is responsible for distributing the events to the relevant parties. The Channel places the events in a specialized queue, often called Topic. Consumers listen to this queue and grab the event.
Implementation details vary widely between channels. RabbitMQ works differently than Kafka that works differently than WebHooks, etc.
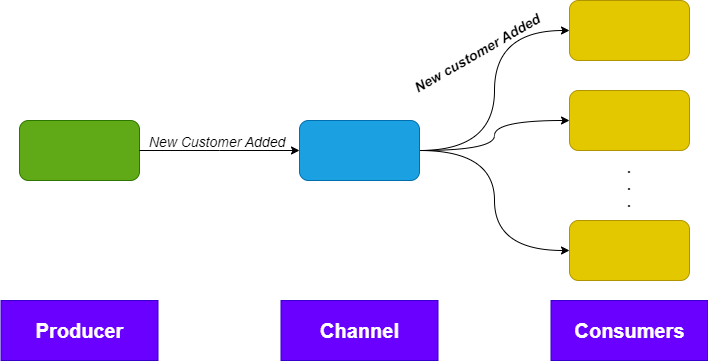
The channel’s method of distribution varies between channels and can be: Queue, REST API call, Proprietary listener. can be developed in any development language compatible with the Channel’s libraries.
7. Consumer
Consumer is the component that receives the event sent by the Producer and distributed by the Channel. Processes the event. Sometimes reports back when processing is complete.
Consumer gets event using either: Push or Pull. The method depends on the Channel.

8. Advantage of Event Driven Architecture (EDA)
- Resolves the three major problems with Command and Query:
- Performance:
- EDA is asynchronous architecture.
- The Channel does not wait for response from customer.
- No performance bottlenecks.
- Coupling:
- The producer sends events to the Channel.
- The Channel distributes events to the topics/queues.
- Both have no idea who’s listening to the event (except in WebHooks).
- No coupling.
- Scalability:
- Many Consumers can listen to events from Channel.
- More can be added as needed.
- Channel doesn’t care, Producer doesn’t know.
- Fully scalable.
- Performance:
9. Orchestration and Choreography
Event Driven Architecture usually employs one or two architectural styles:
- Orchestration
- Flow of the events in the system is determined by a central orchestrator.
- Orchestrator receives output from components and calls the next component in the flow.
- The next component sends the output back to the orchestrator etc.

Orchestration benefits:
- Logic is defined in a single place – easier to maintain.
- Central traffic gateway – easier monitoring and logging.
- Choreography
- No central “knowing all” component.
- Each component notifies about the status of events.
- Other components listen to the events and act accordingly.

Choreography benefits:
- Performance – no middleman.
- Realiability – if one component fails, the rest still work.
The mentioned approaches became popular with EDA and do not constrained to EDA only.
10. Event Sourcing Pattern
Event Sourcing is a data store pattern in which every change in the data is captured and saved. Database stores list of changes for the entity, but not the entity itself. No updates or deletes, just inserts. Every row documents a change in a property of the entity. In this pattern, the database is called Event Store.

11. CQRS Pattern
This pattern stands for: Command and Query Responsibility Segregation. Means:
- Separating the commands (updates/inserts/deletes) from the queries.
- Each one of them in a separate database.
- Commands database is implemented as Event Store to improve performance and simplicity.
- Queries database stores entities.
- Database are synced using a central synchronization mechanism.


12. When to use Event Sourcing and CQRS
- Scalability:
- Scalability is a non-issue in EDA.
- New consumers can be added as needed with no changes to the architecture.
- Great for fluctuation load.
- Asynchronous:
- In internal service communication can be asynchronous, consider EDA (EDA is async by nature).
- Check how many synchronous interactions there are.
- Usually mainly queries.
- The more synchronous calls – the less EDA is relevant.
- Reliable Network:
- EDA utilizes a lot of traffic.
- Network should be reliable or performance will be slow.
- When not to use EDA:
- Small systems with a few services.
- Synchronous-oriented systems (Information system serving mainly queries from end users).
13. Stateless EDA
There are 2 main patterns in implementing EDA: Stateless and Stateful. Related to consumers behaviour.
Each event handled by a consumer is completely autonomous and is not related to past/future events. Should be used when the event is an independent unit with its own outcomes.

- It doesn’t matter which consumer is handling the event.
- The outcome is always the same.
- Should be used when each event is autonomous.
- Not: has nothing to do with the question of what data s contained in the event and whether a call to a DB is required.
14. Stateful EDA
Events might be related to past/future events. Should be used mainly for aggregators and time-related events. Examples: send an email if more than 5 failure events were received in a single minute or calculate the amount of orders submitted in an hour.

- It’s extremely important which consumer handles the event.
- Current state is stored in specific consumer(s).
- Should be used when events are part of a chain of events.
Problems with Stateful EDA:
- Load balancing:
- since the state is stored in a specific consumer, subsequent event must be routed to the same consumer.
- no load balancing is possible.
- Scalability.
It’s better to use the Stateless EDA unless the business requirements force to use the Stateful.
15. Event Streaming
Event Streaming engines publish stream of events:
- E.g. Telemetry from sensors, system logs etc.
- The events are published to a “stream”
- Consumers subscribe to specific stream.
- Events are retained in a stream for a specified amount of time.
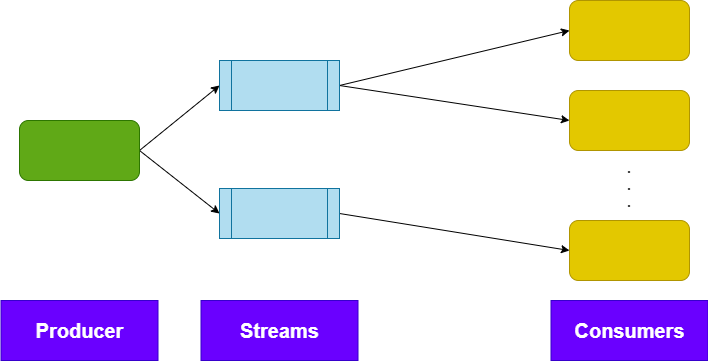
- Consumers can retrieve events that were sent in the past (usually up to a few days)
- Streaming Engine can be used as a central DB. A single source of truth.
- Not all events are necessarily handled. Some might be not relevant.

It’s recommended to use the Event Streaming when the system needs to handle stream of events from the outside: e.g. sensor data, logs, etc. When events should be retained for future use and when high load is expected.
16. Correlation Id
Correlation Id handles the following problems
- Timestamps not synced.
- Different destinations.
- Many records, hard to trace.
At the beginning of each transaction, a unique identifier is attached to the message. This identifier is logged as part of the log record. Allows tracing across components.
17. Mixing EDA and Request/Response
Most EDA systems are not pure EDA. Main reason: UI Clients need responsiveness and use Web API to call the backend. If client only asks for data, EDA will probably won’t work.
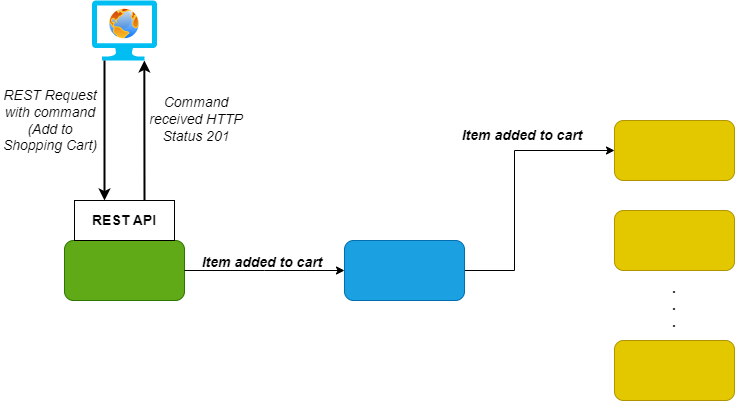
18. Events as Source of Truth
With traditional systems, the DB holds the operational data and the events trigger actions in the system.

With channels that retain events, the channel can function as the source of truth:

Relevant only if:
- Events are retained.
- The channel has some kind of query language.
- Main functionality of the system is around event streaming, no complex interaction.
For example, Apache Kafka suits the best for the mentioned approach, it’s designed for the event streaming.
19. The Saga Pattern
Transaction management in distributed system is difficult.

To resolve this problem, there is 2-phase commit protocol exists, but difficult to implement. So there is the Saga pattern which strives to solve this problem, which sequence of service-scoped transaction, triggered by events. Each transaction is scoped to the service. Means if service B cannot commit the data, then the service A will do something to neutralize this error.
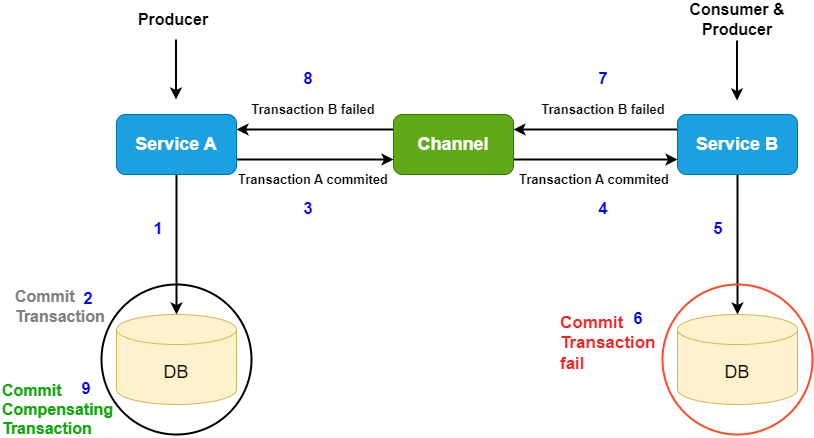
This pattern is not easy to implement. But consistency is still not ensured – compensating transaction can fail as well and data will be inconsistent. Quite difficult to debug and monitoring is important.
When to use?
- When is no need to strongly coupled transactions, means some transactions can be lost.
- Can be used when compensation transaction can be defined: rollback, make a flag, etc.
Hence if the data must be consistent no matter what – there is no bullet proof solution for this problem.
